Грамматика языка – это множество правил, позволяющих определить, какие последовательности слов приемлемы в качестве предложений этого языка. Она определяет, как из слов образуются словосочетания и какие последовательности этих словосочетаний допустимы. Если задана грамматика некоторого языка, то для любой последовательности слов мы можем сказать, является ли она допустимым предложением. И в случае, когда это предложение действительно является допустимым, в результате проверки мы определим, какие естественные группы слов имеются и как они связаны друг с другом. То есть будет определена внутренняя структура предложения.
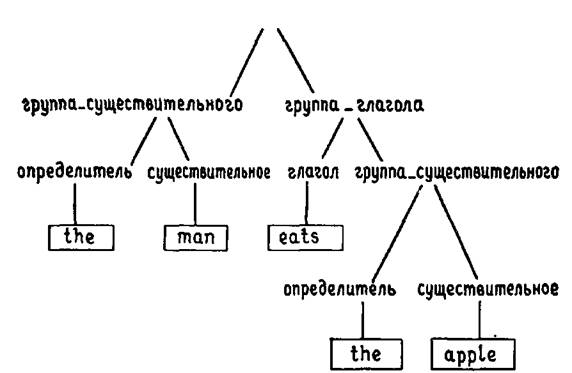
Очень простой класс грамматик составляют так называемые контекстно-свободные грамматики. Вместо того, чтобы давать формальное определение понятия контекстно-свободной грамматики, мы проиллюстрируем его на одном простом примере. Приведенные ниже правила можно рассматривать как начальную часть грамматики предложений английского языка:
предложение--› группа_существительного, группа_глагола.
группа_существительного--› определитель, существительное.
группа_глагола--› глагол, группа_существительного.
группа_глагола--› глагол.
определитель--› [the].
существительное--› [apple].
существительное--› [man].
глагол--› [eats].
глагол--› [sings].
группа_существительного(Х):- присоединить(Y,Z,Х), определитель(Y), существительное(Z).
группа_глагола(Х):- присоединить(Y,Z,Х), глагол(Y), группа_существительного(Z).
группа_глагола(Х):- глагол(Х).
1. Целью является предложение(thе, man, eats, the, apple]).
2. Разбиение исходного списка на два списка Y и Z. Возможны следующие варианты разбиения;
Y = [], Z = [the,man,eats,the,apple] Y = [the], Z = [man,eats,the,apple]
Y= [the,man], Z = [eats,the,apple]
Y= [the,man,eats], Z = [the,apple]
Y= [the,man,eats,the], Z = [apple]
Y= [the, man, eats, the, apple], Z = []
3. Выбор варианта значений для Y и Z из приведенного выше списка вариантов и проверка принадлежности Y классу группа_существительного. То есть, попытка согласования подцели группа_существительного(Y).
4. Если группа_существительного выполняется для Y, то перейти к группа_глагола. Иначе возвратиться к шагу 3 и попробовать другой вариант.
phrase (P,L) истинно, если список L является допустимым словосочетанием типа Р.








 Код
Код Прочитал обе статьи, интересно стало, как сделать выделения слов близких по смыслу "Word2Vec в режиме «skipgrams» — то есть в режиме выделения слов по их окружению, тогда как вторая выдача — Word2Vec в режиме «bag of words» — выделение слов вместе с их окружением."
Прочитал обе статьи, интересно стало, как сделать выделения слов близких по смыслу "Word2Vec в режиме «skipgrams» — то есть в режиме выделения слов по их окружению, тогда как вторая выдача — Word2Vec в режиме «bag of words» — выделение слов вместе с их окружением."


 Поиск
Поиск Друзья
Друзья Администрация
Администрация