| RTCG | - RTCG - особенности работы |
RTCG - особенности работы
Зачем создавался новый язык
Первый кодогенератор, который появился для пакета Windows и был вынесен в отдельный модуль представлял из себя очень простой линковщик, занимающийся только лишь построением файла с кодом целевого языка, в котором были описаны лишь связи между точками элементов схемы. Эффективность такого подхода была слишком низкой, чтобы добиться сборки программ, скорость работы которых практически не отличалась бы от той, которая получается при написании программы руками. Поэтому возникла необходимость создания более продвинутого кодогенератора, элементы для которого будут представлять из себя не готовые куски кода для вставки в приложение, а полноценные программы, которые сами будут решать как лучше им сгенерировать код своего элемента в зависимости от того, какую схему собрал пользователь.
Для решения этой задачи можно было выбрать один из двух подходов: взять один из существующих скриптовых языков и дать ему соответствующее окружение, либо написать свой скриптовой язык. Плюсы первого подхода очевидны - мы получаем почти готовое решение из коробки и бонусом к нему готовую документацию по самому языку. Плюсом второго подхода можно лишь выделить возможность включения своих конструкций и фишек в язык, которые бы более эффективно решали поставленную задачу.
Поскольку в кодогенераторе необходимо было прозрачно поддержать логику работу схемы, включающую в себя следующие обязательные пункты:
- возможность реализовать функцию, которая читала бы данные в порядке очереди: верхняя точка, свойство, поток и соответственно имела бы доступ к контексту текущего элемента и текущего метода
- возможность реализовать сложные типы, которые имеют один основной тип и один (или более) подтипов, т.е. помимо простых примитивов вроде число, строка и т.д. нужно уметь объявлять и работать с типами вроде "код, имеющий подтип строка", а так же любым числом пользовательских типов
- возможность прозрачной конвертации типов по заранее заданным правилам
То и было принято решение все таки реализовать свой язык, т.к. возможность реализации выше перечисленных пунктов была под большим сомнением. Причем если первые два это в основном вопрос архитектуры выбранного скрипта и возможности доступа к внутренним его механизмам, то последний пункт без переписывания части кода вряд ли можно было реализовать так, как хотелось бы. Вот небольшой пример того, о чем тут идет речь:
где d - функция чтения данных с точки, свойства или потока. Этот скрипт в зависимости от того, какой тип данных пришел в Text должен бы был сгенерировать один из следующих вариантов кода:
Точно такая же проблема возникает, когда мы хотим в элементе сгенерировать код, который складывает два строковых аргумента и присваивает их чему-то. В зависимости от того, что пришло к нам в качестве аргументов необходимо будет где-то вставить кавычки, где-то применить конверсию типов, где-то на этапе сборке склеить их в одну строку (в случае констант). Чтобы разработчик каждый раз не занимался десятком проверок при необходимости сложить строки или не вызывал специальные функции, а так же не генерировал плохо оптимизированный код, необходимо поддержать эту логику на уровне кодогенератора и лучше всего это делать, если он изначально на это рассчитан.
Для решения этой задачи можно было выбрать один из двух подходов: взять один из существующих скриптовых языков и дать ему соответствующее окружение, либо написать свой скриптовой язык. Плюсы первого подхода очевидны - мы получаем почти готовое решение из коробки и бонусом к нему готовую документацию по самому языку. Плюсом второго подхода можно лишь выделить возможность включения своих конструкций и фишек в язык, которые бы более эффективно решали поставленную задачу.
Поскольку в кодогенераторе необходимо было прозрачно поддержать логику работу схемы, включающую в себя следующие обязательные пункты:
- возможность реализовать функцию, которая читала бы данные в порядке очереди: верхняя точка, свойство, поток и соответственно имела бы доступ к контексту текущего элемента и текущего метода
- возможность реализовать сложные типы, которые имеют один основной тип и один (или более) подтипов, т.е. помимо простых примитивов вроде число, строка и т.д. нужно уметь объявлять и работать с типами вроде "код, имеющий подтип строка", а так же любым числом пользовательских типов
- возможность прозрачной конвертации типов по заранее заданным правилам
То и было принято решение все таки реализовать свой язык, т.к. возможность реализации выше перечисленных пунктов была под большим сомнением. Причем если первые два это в основном вопрос архитектуры выбранного скрипта и возможности доступа к внутренним его механизмам, то последний пункт без переписывания части кода вряд ли можно было реализовать так, как хотелось бы. Вот небольшой пример того, о чем тут идет речь:
// где-то в коде элемента
trace('caption = ' & d("Text"))
// если это была строка, то необходимо добавить к ней кавычки целевого языка слева и справа
caption = "Hello world"
// если это было целое число, то необходимо его привести к строке методами целевого языка
caption = IntegerToString(90)
// ... а еще лучше, если кодогенератор отличит константу от переменной и в нашем случае приведет ее в строку уже на этапе сборки проекта
caption = "90"
// и наконец если в качестве данных пришел какой-то непростой тип, например, массив myArray и нам хотелось бы, чтобы при использовании его в качестве строки выводились все элементы через запятую
caption = myArray.merge(",")
Точно такая же проблема возникает, когда мы хотим в элементе сгенерировать код, который складывает два строковых аргумента и присваивает их чему-то. В зависимости от того, что пришло к нам в качестве аргументов необходимо будет где-то вставить кавычки, где-то применить конверсию типов, где-то на этапе сборке склеить их в одну строку (в случае констант). Чтобы разработчик каждый раз не занимался десятком проверок при необходимости сложить строки или не вызывал специальные функции, а так же не генерировал плохо оптимизированный код, необходимо поддержать эту логику на уровне кодогенератора и лучше всего это делать, если он изначально на это рассчитан.
Недостатки RTCG
Основные недостатки кодогенератора связаны с возможностью дальнейших оптимизаций. Наиболее актуальная проблема при написании элементов пакета это невозможность точно узнать, сколько раз будет вызван тот или иной его метод. Это знание необходимо в том случае, если код элемента можно сделать гораздо оптимальнее для случая когда он используется только один раз и случая, когда он используется несколько раз. Простой пример:
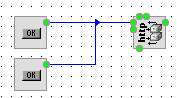
В этой схеме по нажатию кнопки происходит запрос данных с сервера и код запроса состоит из нескольких строк кода. Поскольку элемент не знает, сколько кнопок используется для отправки запроса, то он тупо сгенерирует код для каждого из вызовов своего метода и в итоге получится примерно следующее:
Т.е. один и тот же код будет использован дважды для каждой из кнопок. Хочется сразу же воскликнуть - так почему бы не проверять наличие HabEx, присоединенного к методу отправки запроса, и генерировать нужный код для каждого из случаев? Да, это действительно можно сделать, но нужно помнить о том, что кроме HabEx если еще просто Hub, есть еще ChannelToIndex и гора других элементов, которые могут работать схожим образом и о которых разработчик элемента вообще может не знать. Кроме того между HubEx и методом элемента может стоять любой другой элемент (или даже несколько) и тогда подобная проверка вообще утратит всякий смысл.
Хорошо, тогда почему бы изначально не вынести метод элемента в отдельную функцию и вызывать её всякий раз? Т.е. получить такой код:
Казалось бы проблема решена, но что если схема собрана вот так:
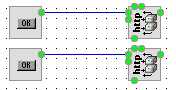
Тогда наш код получится таким:
И снова мы пришли к тому, с чего начали, только теперь в код добавились лишние вызовы receiver и код стал менее оптимальным, чем был бы без наших оптимизаций. И снова тут можно воскликнуть - так почему бы код функции receiver не сгенерировать один раз и все данные для него передать в аргументах? Да, так действительно можно сделать, но достаточно часто настройки элемента сильно меняют генерируемый им код и вынос их в параметры снова сделает его менее оптимальным, чем он мог бы быть. Как минимум будут присутствовать проверки, которых могло бы не быть и сам код был бы короче.
Но в любом случае все эти оптимизации не применимы для случаев, когда повторно используется не один элемент, а их набор. Такую ситуацию может обработать только кодогенератор и только он мог бы знать, какие части схемы используются повторно, чтобы вынести их в отдельную функцию. Однако для этого кодогенератор должен обладать как минимум двух проходным циклом - на первой итерации элементы должны вызываться по цепочки и для каждой точки элемента необходимо считать количество использований, а уже вторым проходом генерировать собственно код и вставить функции в те части схемы, с которых начинается повторное использование.
В этой схеме по нажатию кнопки происходит запрос данных с сервера и код запроса состоит из нескольких строк кода. Поскольку элемент не знает, сколько кнопок используется для отправки запроса, то он тупо сгенерирует код для каждого из вызовов своего метода и в итоге получится примерно следующее:
button1.onclick = function () {
openconnection(...);
senddata(...);
readdata(...);
};
button2.onclick = function () {
openconnection(...);
senddata(...);
readdata(...);
};
Т.е. один и тот же код будет использован дважды для каждой из кнопок. Хочется сразу же воскликнуть - так почему бы не проверять наличие HabEx, присоединенного к методу отправки запроса, и генерировать нужный код для каждого из случаев? Да, это действительно можно сделать, но нужно помнить о том, что кроме HabEx если еще просто Hub, есть еще ChannelToIndex и гора других элементов, которые могут работать схожим образом и о которых разработчик элемента вообще может не знать. Кроме того между HubEx и методом элемента может стоять любой другой элемент (или даже несколько) и тогда подобная проверка вообще утратит всякий смысл.
Хорошо, тогда почему бы изначально не вынести метод элемента в отдельную функцию и вызывать её всякий раз? Т.е. получить такой код:
function receiver(url) {
openconnection(...);
senddata(...);
readdata(...);
}
button1.onclick = funcion() {
receiver();
}
button2.onclick = funcion() {
receiver();
}
Казалось бы проблема решена, но что если схема собрана вот так:
Тогда наш код получится таким:
function receiver1(url) {
openconnection(...);
senddata(...);
readdata(...);
}
function receiver2(url) {
openconnection(...);
senddata(...);
readdata(...);
}
button1.onclick = funcion() {
receiver1();
}
button2.onclick = funcion() {
receiver2();
}
И снова мы пришли к тому, с чего начали, только теперь в код добавились лишние вызовы receiver и код стал менее оптимальным, чем был бы без наших оптимизаций. И снова тут можно воскликнуть - так почему бы код функции receiver не сгенерировать один раз и все данные для него передать в аргументах? Да, так действительно можно сделать, но достаточно часто настройки элемента сильно меняют генерируемый им код и вынос их в параметры снова сделает его менее оптимальным, чем он мог бы быть. Как минимум будут присутствовать проверки, которых могло бы не быть и сам код был бы короче.
Но в любом случае все эти оптимизации не применимы для случаев, когда повторно используется не один элемент, а их набор. Такую ситуацию может обработать только кодогенератор и только он мог бы знать, какие части схемы используются повторно, чтобы вынести их в отдельную функцию. Однако для этого кодогенератор должен обладать как минимум двух проходным циклом - на первой итерации элементы должны вызываться по цепочки и для каждой точки элемента необходимо считать количество использований, а уже вторым проходом генерировать собственно код и вставить функции в те части схемы, с которых начинается повторное использование.
BB-code статьи для вставки
Всего комментариев: 0
(комментарии к статье еще не добавлены)
 Поиск
Поиск Друзья
Друзья Администрация
Администрация